
这篇文章是在看完 Go 语言设计与实现前两章词法分析及语法分析后的总结,作者尽量站在宏观的角度,说一下 Go 语言中的词法分析和语法分析,尽量不涉及具体的源码探索。
词法分析
词法分析(lexical analysis)是 计算机科学 中将字符序列转换为标记(token)序列的过程——词法分析 - 维基百科,自由的百科全书。
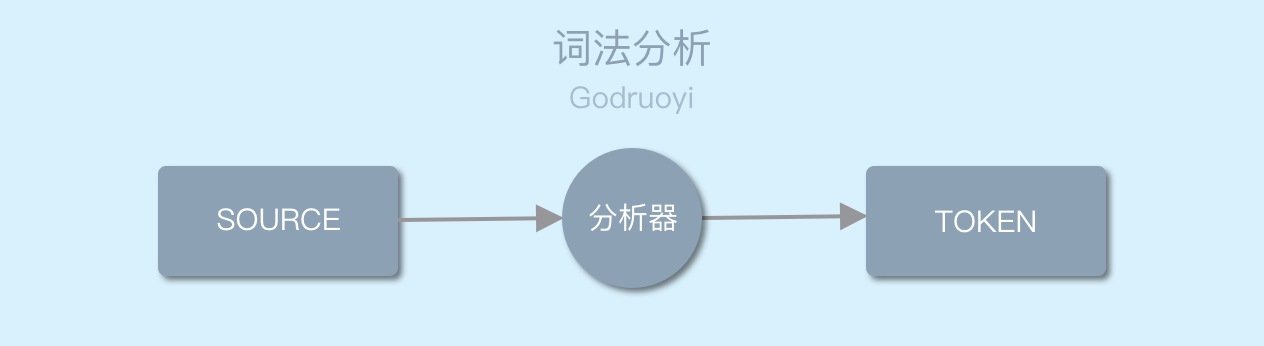 图 1.0 词法分析
图 1.0 词法分析
可以简单的理解为将源代码按一定的转换规则,翻译为字符序列的过程。
如给定的如下转换规则:
%%
package printf("PACKAGE ");
import printf("IMPORT ");
func printf("FUNC ");
\. printf("DOT ");
\{ printf("LBRACE ");
\} printf("RBRACE ");
\( printf("LPAREN ");
\) printf("RPAREN ");
\" printf("QUOTE ");
\n printf("\n");
[0-9]+ printf("NUMBER ");
[a-zA-Z_]+ printf("IDENT ");
%%其中第一条规则表示将源代码中的 package 翻译为 PACKAGE,其他类似;若用该规则来翻译如下的源代码:
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello")
}则输出的 Token 序列为:
PACKAGE IDENT
IMPORT LPAREN
QUOTE IDENT QUOTE
RPAREN
FUNC IDENT LPAREN RPAREN LBRACE
IDENT DOT IDENT LPAREN QUOTE IDENT QUOTE RPAREN
RBRACE
输出的 Token 序列已经看不出是什么语言了;当然,这种纯字符的 Token 对后续的分析帮助不大,一般分析器都会把他封装为一个结构体,以包含更多信息。
type tokenx struct {
tok token // 解析的 Token 序列(如上的 IDENT)
lim string // 原始值(如 main)
}语法分析
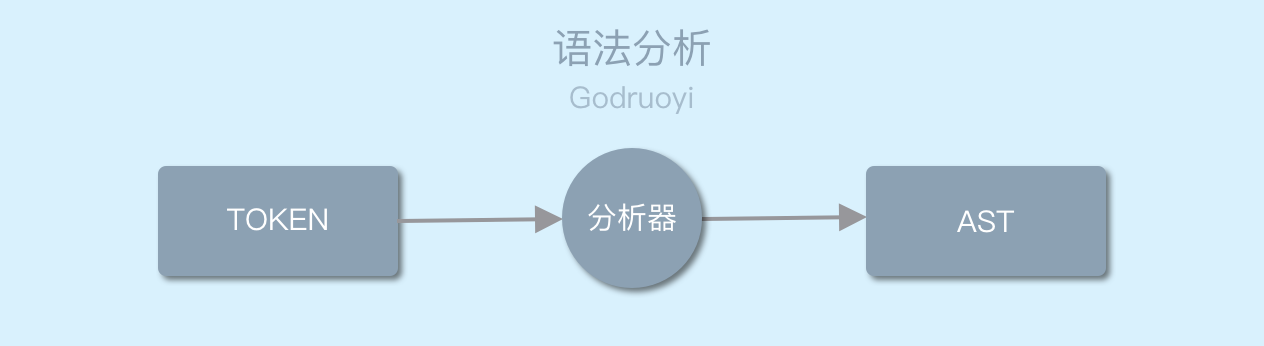 图 2.0 语法分析
图 2.0 语法分析
语法分析是将词法分析的输出当作输入,按照给定的语法格式进行分析并确定其语法结构的一种过程。
举个列子,假设输入序列为 S,对应的语法规则为:
S -> E + F
其含义为输入序列 S 可以表示为两个子项 E、F 相加;而 E 可以表示为:
E -> E + F
-> F
其含义为 E 可以分解为两个子项 E、F 相加;或分解为一个单独的 F 项;
F -> num{1, 2, 3, 4, 5}
而 F 表示数字集合,假设只有上述数字集合,即 F ∈ {1, 2, 3, 4, 5}。
则下面的字符序列都是有意义的,即给定的字符序列 S,是否能从语法规则中被推导出来
1 + 1
1 + 2
2 + 3 + 4
1 + 2 + 3 + 4
1 + 3 + 2 + 4 + 5
假设给定的字符序列 S 为 2 + 3 + 4,按上述的规则 S -> E + F,分步推到如下(按最右推导,即从最右边字符开始):
- S -> E + F // 原规则
- S -> E + 1 // 将 F 解析为数字 1,1 ≠ 4 继续回溯
- S -> E + 2 // 2 ≠ 4 继续回溯
- S -> E + 3 // 3 ≠ 4 继续回溯
- S -> E + 4 // ok,数字 4 已最小不可分解
- S -> (E + F) + 4 // 将 E 按推导为 E + F 格式
- S -> (E + 1) + 4 // 将 F 解析为数字 1,1 ≠ 3 继续回溯
- S -> (E + 2) + 4 // 将 F 解析为数字 2,2 ≠ 3 继续回溯
- S -> (E + 3) + 4 // ok
- S -> (F + 3) + 4 // 将 E 按推导为 F 格式
- S -> (1 + 3) + 4 // 将 F 解析为数字 1,1 ≠ 2 继续回溯
- S -> (2 + 3) + 4 // ok
即通过给定的规则,推导出字符串 S1,该字符串和原始字符序列 S 相等,语法分析即认为该输入序列是合法的。
而下面的字符序列是无效的,即语法错误;
7 + 1 // 不合法,不可能推出数字 7
1 + 2 + 6 // 不合法,不可能推出数字 6
可以看到,语法分析器将采用递归的思想,一层一层分析,直到子项不可再分;具体的推导过程推荐观看 编译原理 — 中科大_哔哩哔哩 P39。
Go 语言的词法分析 & 语法分析
Go 语言中的词法分析和语法分析是放在一起进行的;经过这一步,最终将源代码生成抽象语法树。
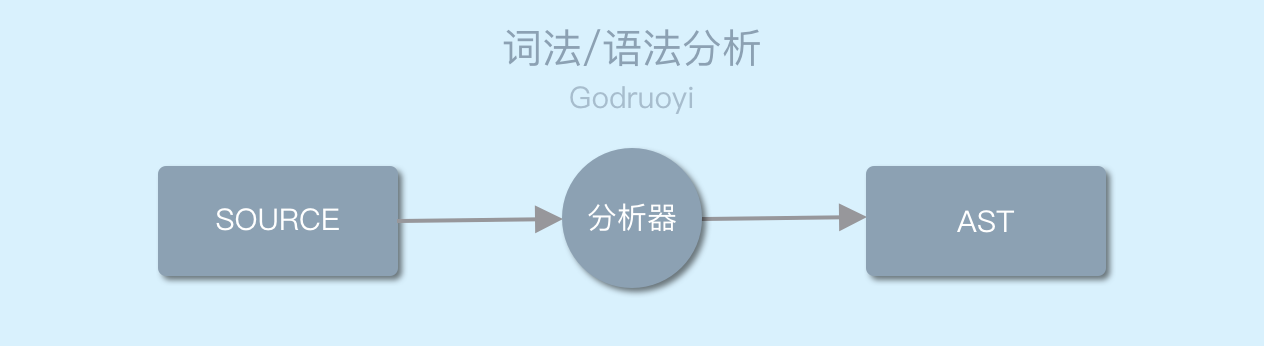 图 3.0 Go语言的词法分析与语法分析
图 3.0 Go语言的词法分析与语法分析
作者将通过下面的列子来探索 Go 语言的词法分析过程。假设目标文件夹中有两个文件 hello.go 和 main.go,其内容如下;
// main.go
package main
import "fmt"
func main() {
fmt.Println(Hello)
}
// hello.go
package main
var Hello string = "Hello world"Go 语言的编译器入口是在 src/cmd/compile/main.go;在进行一些初始化准备工作后,编译器获取待解析的文件数组,并将其交给 Go 语言解析器负责解析。
var filenames = []string{
"main.go",
"hello.go",
}
// src/cmd/compile/internal/gc/main.go:578
parsefiles(filenames)解析器会利用多个 goroutine 来并发解析源文件,其 goroutine 数量取决于处理器的核心数 + 10,主要作用是为了控制同时打开的文件数量。
// Limit the number of simultaneously open files.
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
for _, filename := range filenames {
go func(filename string) {
sem <- struct{}{}
defer func() { <-sem }()
file := syntax.Parse(os.Open(filename))
}(filename)
}
// waitsyntax.Parse 解析器会将每一个源文件解析为一个 source 结构体,其简化的格式如下:
type source struct {
buf []byte // 源代码字节数组
ch rune // 指向当前解析的字符
b,r,e int // 指向buf数组的开始/当前扫描字符/结束指针
}解析器在初始化时,会将 buf 初始化为一个 4k 大小的空 slice,并将第一个字节设置为空格 ' ',如图所示:
 图 3.1 buf初始化
图 3.1 buf初始化
然后解析器开始一个字符一个字符的读取并分析,但由于 buf 目前是空的,第一次解析时会尝试读取目标文件内容到 buf 中;针对上面的 main.go 文件,读取后 buf 内容为:
 图 3.2 读取文件内容
图 3.2 读取文件内容
接下来,解析器会尝试从 buf 中一个字符一个字符的读取,再遇到 ' ', \n, \t, \r 等字符时分离。
for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}针对图 3.2 的 buf 内容,第一次操作结束后,扫描器中的 b,r,e 指针如下图所示:
b: begin 开始位置;r: read 当前读取到的位置;e: end 结束位置。
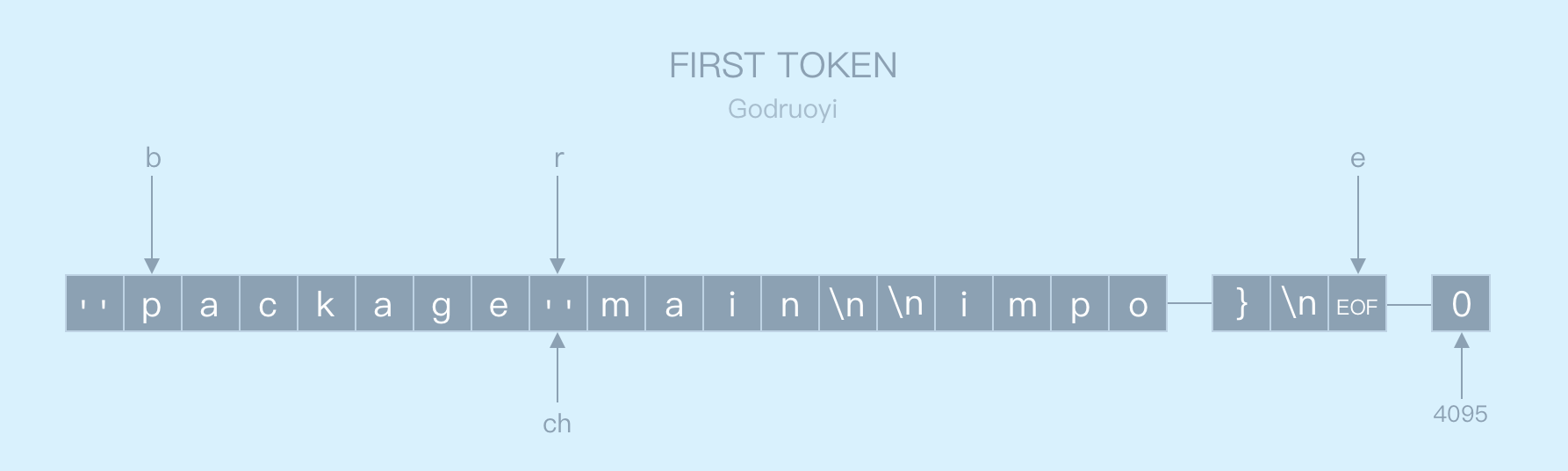 图 3.3 解析第一个 token
图 3.3 解析第一个 token
解析器通过 b,r 指针计算(类似 buf[b:r])出本次解析获得的字符串 package;再和 Go 预定义的关键字列表对比后,最终将设置当前 sacnner 扫描器的 tok 属性设置为 _Package。
第一次解析结束后,扫描器的各个属性如下图所示:
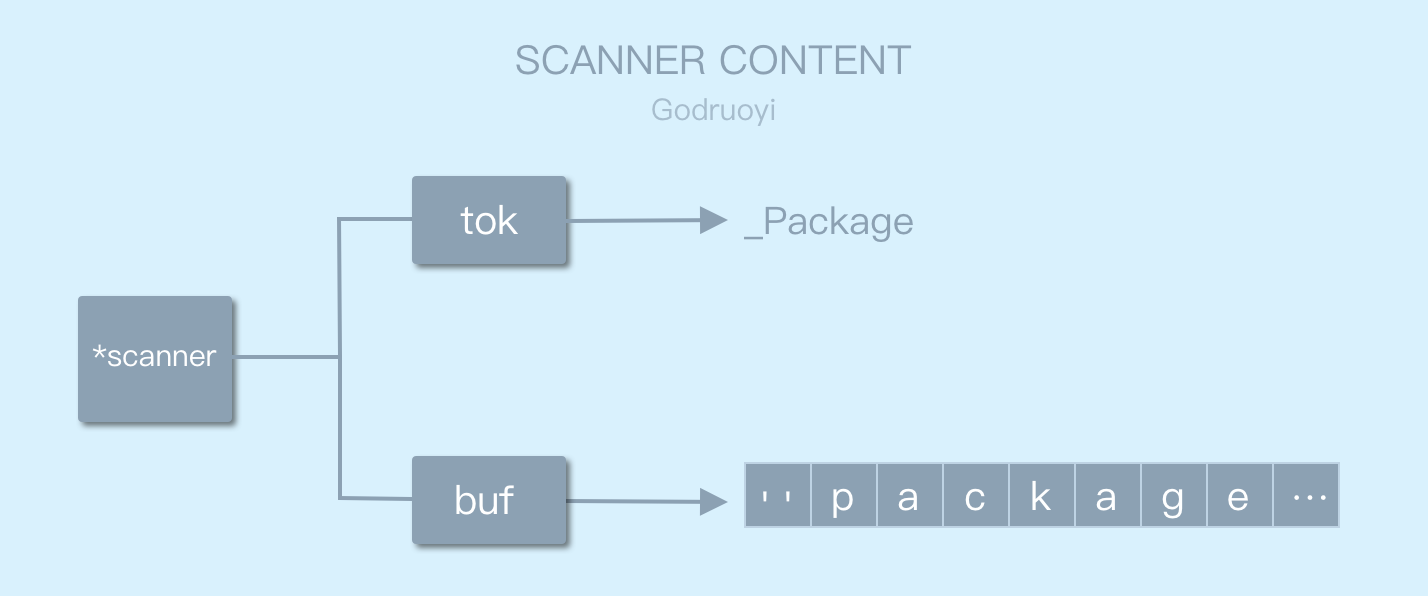 图 3.4 扫描器scanner基本属性情况
图 3.4 扫描器scanner基本属性情况
Go 语言的词法分析是渐渐试的,在获得第一个 token 后,解析器尝试初始化 SourceFile;每一个 SourceFile 对应一个 go 文件,其中包含包的名称,变量、常量、函数等的全部定义,其简化结构如下:
type File struct {
PkgName *Name // package name
DeclList []Decl // 包含包名/变量/常量/函数等的定义
}Go 源码中使用 fileOrNil 方法初始化 file,解析器将检查第一个 token 是否为 pakcage,否则将报错;毕竟所有的 go 文件都是以 package 开头的。
// 伪代码
func fileOrNil() {
f := new(File)
if tok != _Package {
p.syntaxError("package statement must be first")
}
f.PkgName = ?
}接下来解析器将设置当前 file 的包名,但此时解析器并不知道具体的包名是什么;不过根据语法规则解析器知道 package 关键字后面一定是跟的包名,只需要解析出下一个 token,该 token 就是对应的包名称。
第二次解析结束后,扫描器中的 b,r,e 指针如下图所示:
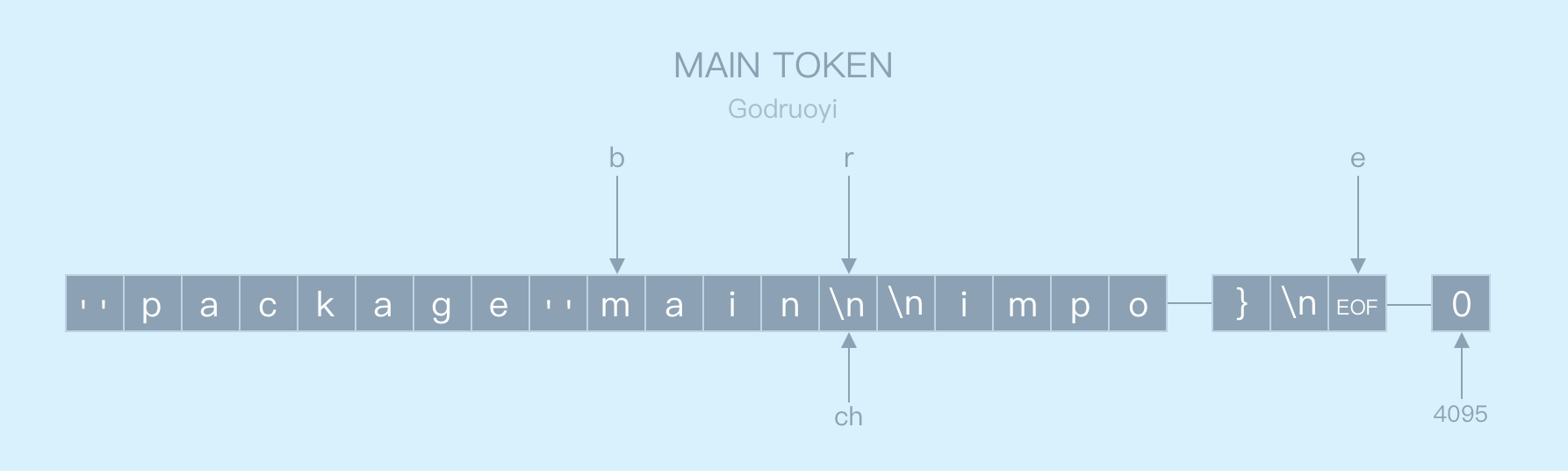 图 3.5 第二次解析结束
图 3.5 第二次解析结束
在需要什么的时候,显示的解析什么,这也是 Go 解析器渐渐试解析的体现。
同样,根据 b,r 指针,计算出当前解析获得的字符串为 main;该字符串非内置 token,Go 语言将设置当前 sacnner 扫描器的 tok 及 limi 属性为 _Name 及 main,其中 lit 是被扫描符号的文本表示。
_Name 一般表示变量名/常量名/方法名等,可以理解为非内置关键字的文本类型。
第二次解析结束后,scanner 的各个属性如下图所示:
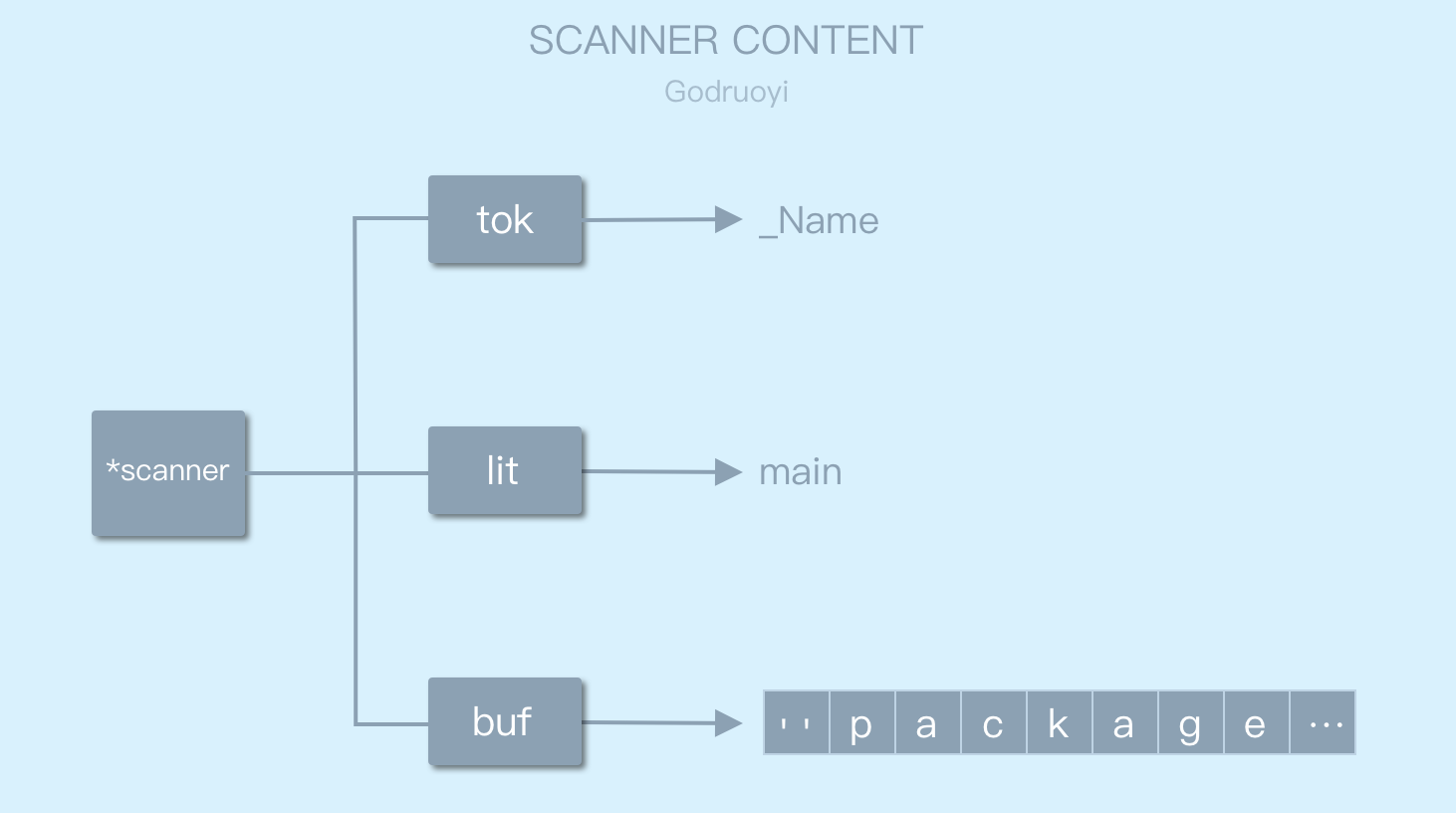 图 3.6 扫描器scanner基本属性情况
图 3.6 扫描器scanner基本属性情况
检查 _Package 及设置当前文件 PkgName 的伪代码如下:
f := new(File)
if tok != _Package {
p.syntaxError("package statement must be first")
}
tok := parser.next() // 伪代码 get next token
if tok != _Name {
// 验证:包名必须是一个 name 类型的 token,
// 可以理解为非内置关键字的文本类型
}
f.PkgName = &Name{Value: "main"} // 伪代码到目前为止,解析器已经成功的初始化 syntax.File 结构并为其 PkgName 属性赋值,如图 3.7:
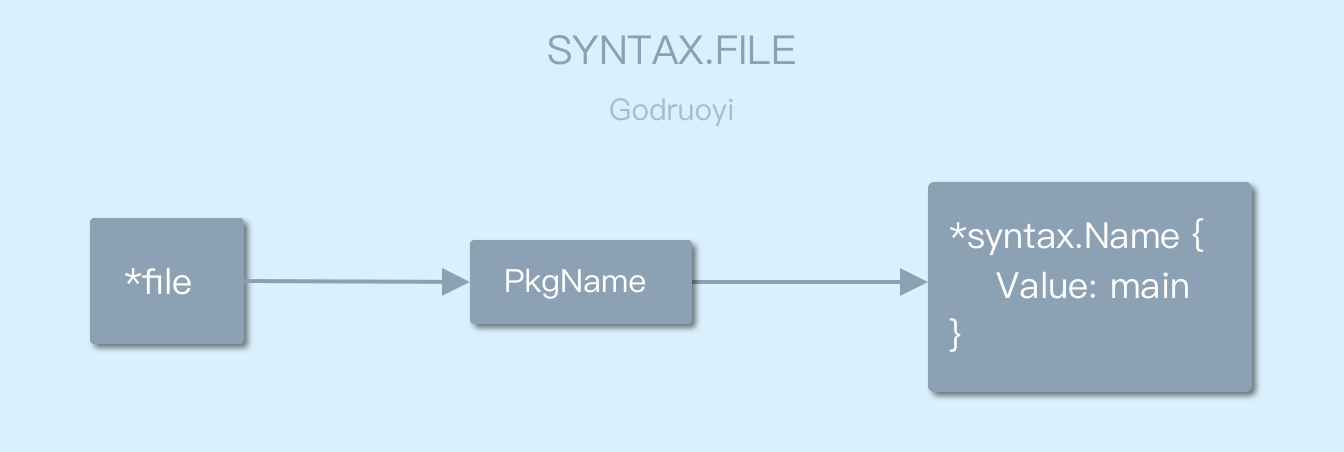 图 3.7 syntax.File 属性
图 3.7 syntax.File 属性
接下来,解析器将开始分析 Go 语言的 import 关键字,这部分作者将在后面的文章中继续输出。
// { ImportDecl ";" }
for p.got(_Import) {
f.DeclList = p.appendGroup(f.DeclList, p.importDecl)
p.want(_Semi)
}