
由于自己最近在学习 @张磊 老师的 Kubernetes 专栏,以下内容均来自每节专栏学习后的感悟、总结。张老师的Kubernetes专栏通俗易懂,欢迎大家跟我一起加入学习。
容器的本质
容器的本质是一个进程,进程与进程之间相互隔离造就了容器与容器互不影响的特性。在启动一个容器(即创建一个进程时),通过 Namespace 技术实现容器的隔离、通过Cgroups 来实现容器的资源控制。
Namespace
容器进程的创建通过 Linux 平台下的 clone 方法创建,在调用该方法创建进程时,通过指定额外的 Namespace 参数,使得刚创建的进程属于一个独立的空间。
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL)指定额外参数 CLONE_NEWPID 创建的新进程,有一个自己的 独立进程空间,在这个空间里,它的进程 ID 为 1。它既看不到其在宿主机的真正进程、也看不到其他容器的进程。
其实这都是假象,创建的该进程在宿主机上是真实存在的,并且也受宿主机的管理和控制,也享受宿主机的资源。但在该进程内部,它处于一个独立的空间,只看得到该进程一个资源,让其误以为自己处于一个密闭的 盒子 内。这
这,就是 Linux 容器最基本的实现原理了!
你可能也注意到了,虽然通过 Linux Namespace 技术实现了进程的相互隔离,但这种隔离机制只是为不同的容器进程指定不同的 namespace,但不同的容器进程其实在宿主机上是真实存在的,并且也使用相同的宿主机内核。这也是容器在和虚拟化技术相比下,隔离得不够彻底的原因。
Cgroups
容器进程创建好后,若不进行其他处理,该进程运行时所消耗及占用的资源(如 CPU、内存)等;是可以被其他宿主机进程或其他容器进程享用的。为了解决这个问题,Linux 容器设计中引入了 Cgroups 的概念。
Linux Cgroups 的全称是 Linux Control Group,它的主要作用就是限制一个进程能够使用的资源上限(如 cpu、内存、网络等)。
在
Linux中,Cgroups给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的/sys/fs/cgroup路径下。
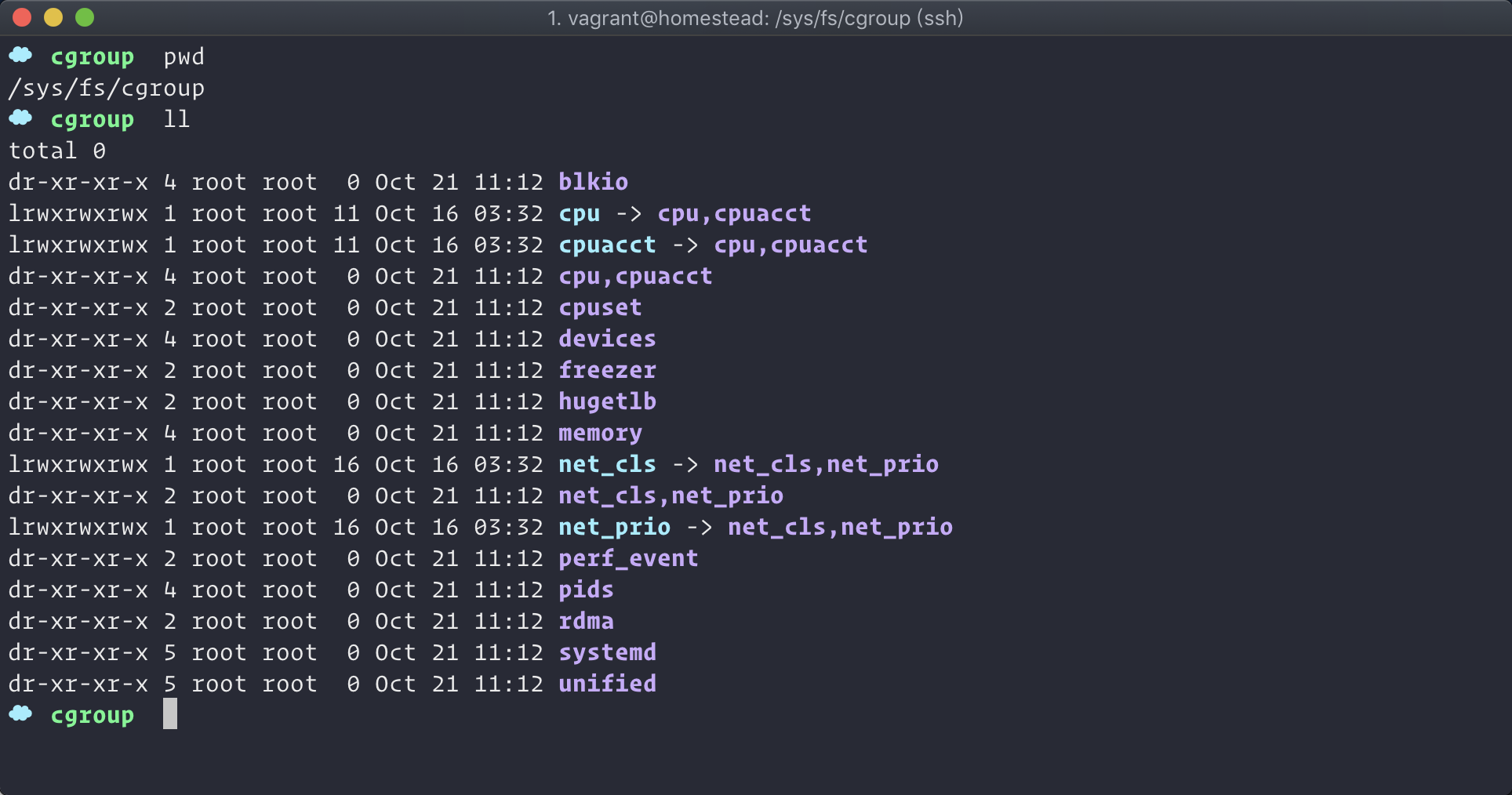
若你的系统中没有挂载该目录,那你需要自行 google 挂载。
在该目录下,你可以看到很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。每个目录下面又有很多配置文件。如你可能在 cpu 目录下看到诸如 cfs_period 和 cfs_quota 这样的配置文件。而这两个配置文件,是限制 CPU 使用率的关键配置项。
这两个参数需要组合使用,可以用来限制进程在长度为
cfs_period的一段时间内,只能被分配到总量为cfs_quota的CPU时间。其中period的默认值为100 ms(毫秒),quota的默认值为-1,即不做限制。当修改quota的值为20 ms时,表示在100ms的时间范围内,cpu只能使用20 ms。也就是说,cpu的使用率最大为20%。
上面说到,容器启动后的进程我们需要用 Linux Cgroups 来限制其资源的访问。接下来我们看看到底是如何进行控制的。
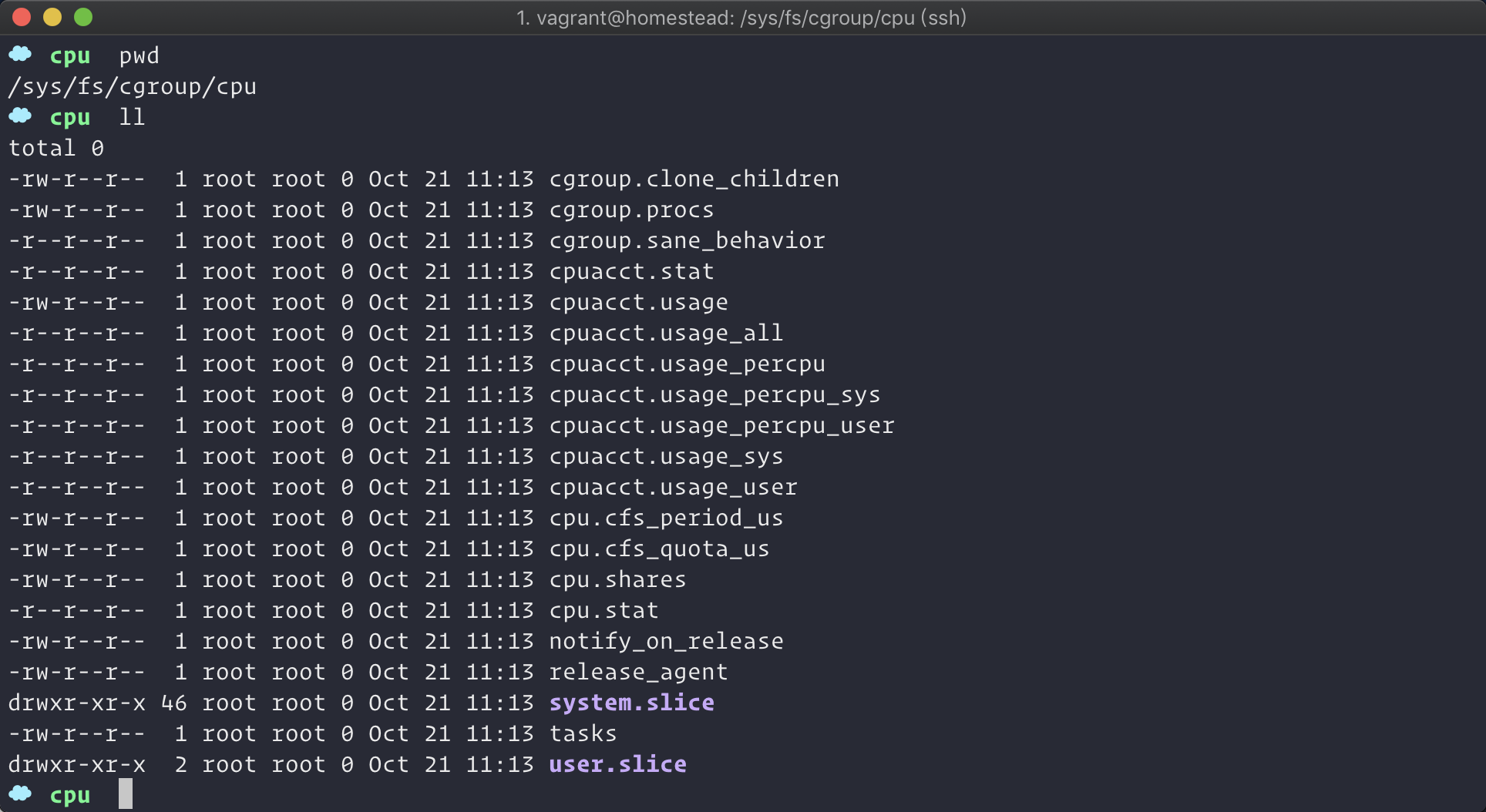
我们在 /sys/fs/cgroup/cpu 目录下创建一个文件夹:
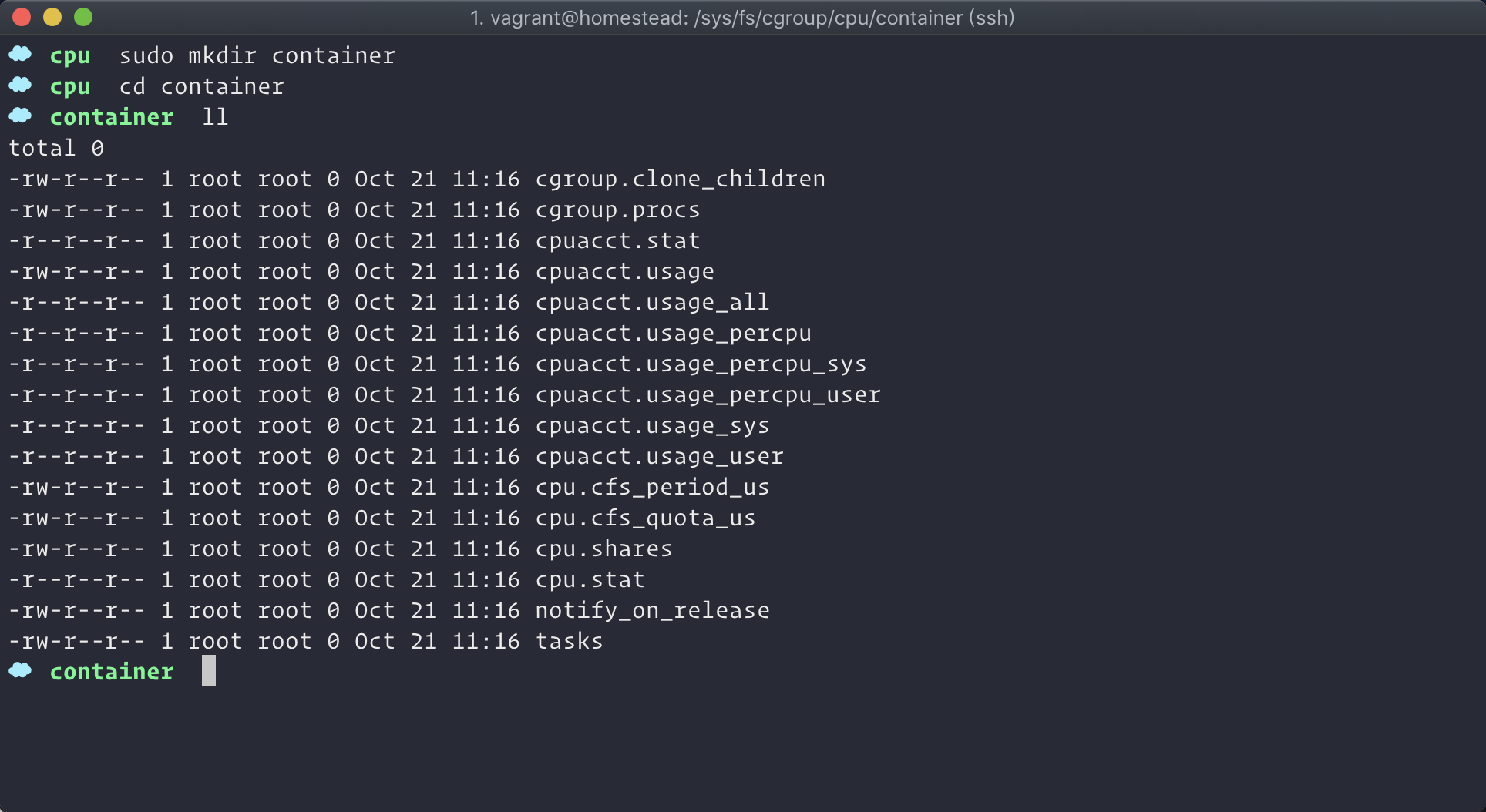
可以看到,我们创建的文件夹里面已经被系统默认创建了一些配置文件。我们把这样一个目录叫做控制组,接下来修改这个控制组的 cpu 使用率为 20% 。
我们在命令行用一个死循环来测试,也使得该进程能占用全部的 CPU。
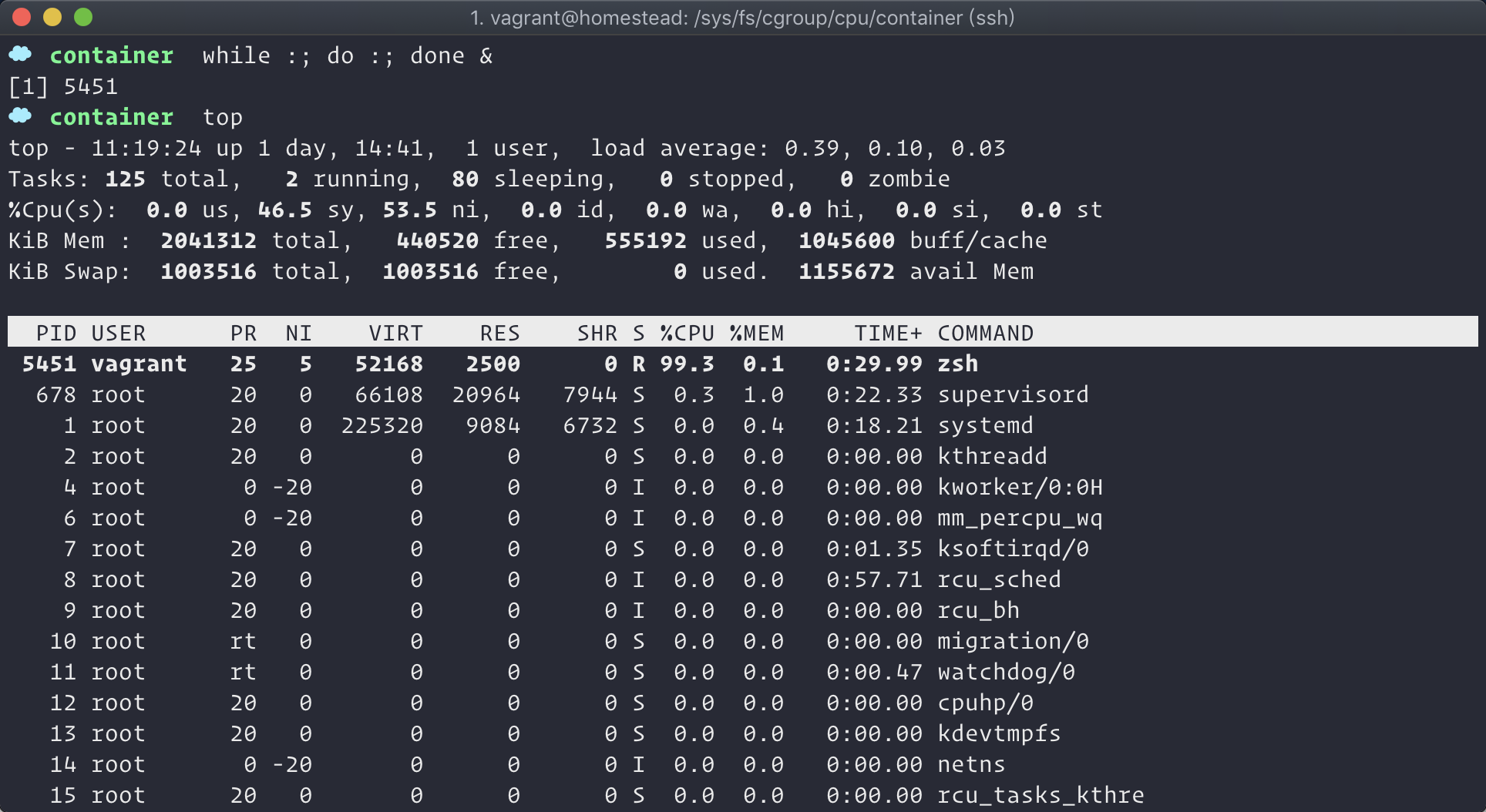
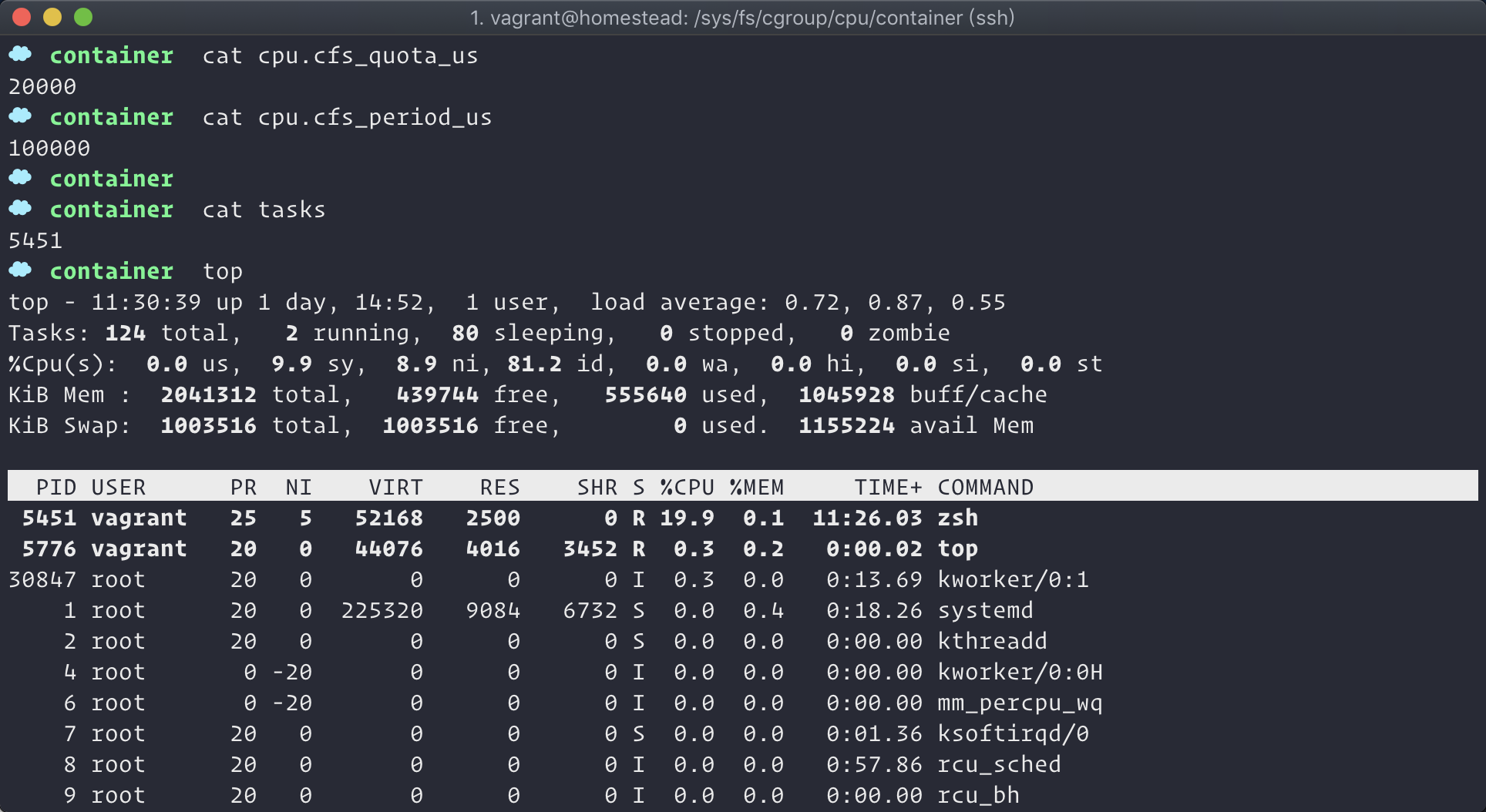
通过 top 参数,我们看到该进程 5451 的 cpu 使用率已经达到 99.3%;由于我们创建该进程时,没有为其指定一个控制组时,他默认将享用全部的 cpu 及内存配置。接下老我们将该进程通过下面的命令加入到刚刚创建的 container 组中去。
$ echo 5451 > /sys/fs/cgroup/cpu/container/tasks
将改进程加入控制组后,改进程的 cpu 使用率一下就从原来的 100% 降到了 20% 左右。
在 docker 中,我们可以在启动容器的时候,指定 cpu 参数来控制该容器的资源占用,如下所示,这样启动的 docker 容器,只能使用 20% 的 cpu。
Docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash当然,通过 Linux Cgroups 还可以限制其他参数,如网络、挂载点、内存等等。
今天就学到这儿了,明天继续吧!!!