
日常工作中我们可能会遇到如下的问题,在未引入数据库事务这一特性前,应用程序在处理这些问题时总显得过于复杂,如:
- 数据库在写入一半数据时崩溃
- 订单数据保存一半后网络链接中断
- 多个客户端可能会同时写入数据库
- 多个客户端之间的条件竞争可能会扰乱整个应用程序
而事务一直是简化这些问题的首选机制。他为上层应用程序提供一个可靠性保障:将多个读写操作组合成一个逻辑单元来执行,要么全部成功,要么全部失败。应用程序在处理这些问题时将不再关心一半成功一半失败的情况,也不再拘泥于下层各种不可靠的系统,因为大多数数据库系统都会从多个维度(事务的ACID)来保证数据的正确性。
计算机发展到今天,我们一直在不可靠的环境中构建可靠的系统。
事务的 ACID
ACID 并不是什么高大上的术语;而是数据库系统在实现事务时为保证其正确可靠而必须满足的几个约束,不同的约束提供了不同的保障。
Atomicity(原子性)
原子性并不是指把事务当作一个整体来运行,既运行过程中不可中断、不可切换;而是指事务再遇到出错时,能终止事务,丢弃该事务的所有变更。事务一旦终止,实现这一特性的数据库会保证数据恢复到原始状态,应用程序不在担心各种可能存在的中间结果,只用专注于处理成功或失败两种状态。
Consistency(一致性)
一致性主要是指数据状态的一致性,考虑这样一个例子:从 A 账户转入 100 元到 B 账户,最终的一致性状态是指 A 账户的支出和 B 账户的收入达到收支平衡。
而在 DDIA 这一书里,作者认为一致性是应用程序的属性,不应该由数据库来实现。拿上面例子来说,账户 A 转出 100 元但由于程序问题账户 B 却收入 200 元,虽然最终状态是收支不平衡,但这并不影响数据库会按正确的方式来保存这些数据。状态是否一致的判断,应该交由应用程序去处理,数据库系统只会正确的保存你给他的所有数据,而不会关心数据本身(参考 ACID 中的 C 是被扔进去拼凑的单词)。
Isolation(隔离性)
当多个 client 同时操作同一数据时,就可能会出现并发问题(race conitions)。事务的隔离性要求并发执行的事务之间互不干扰,如果在一个事务中进行多次写入,则另一个事务要么看到她全部写入结果,要么什么都看不到。
下面的例子就不满足事务的隔离性:User1 先后进行了两次写入,在她未提交前,User1 读取到了部分新增的数据。
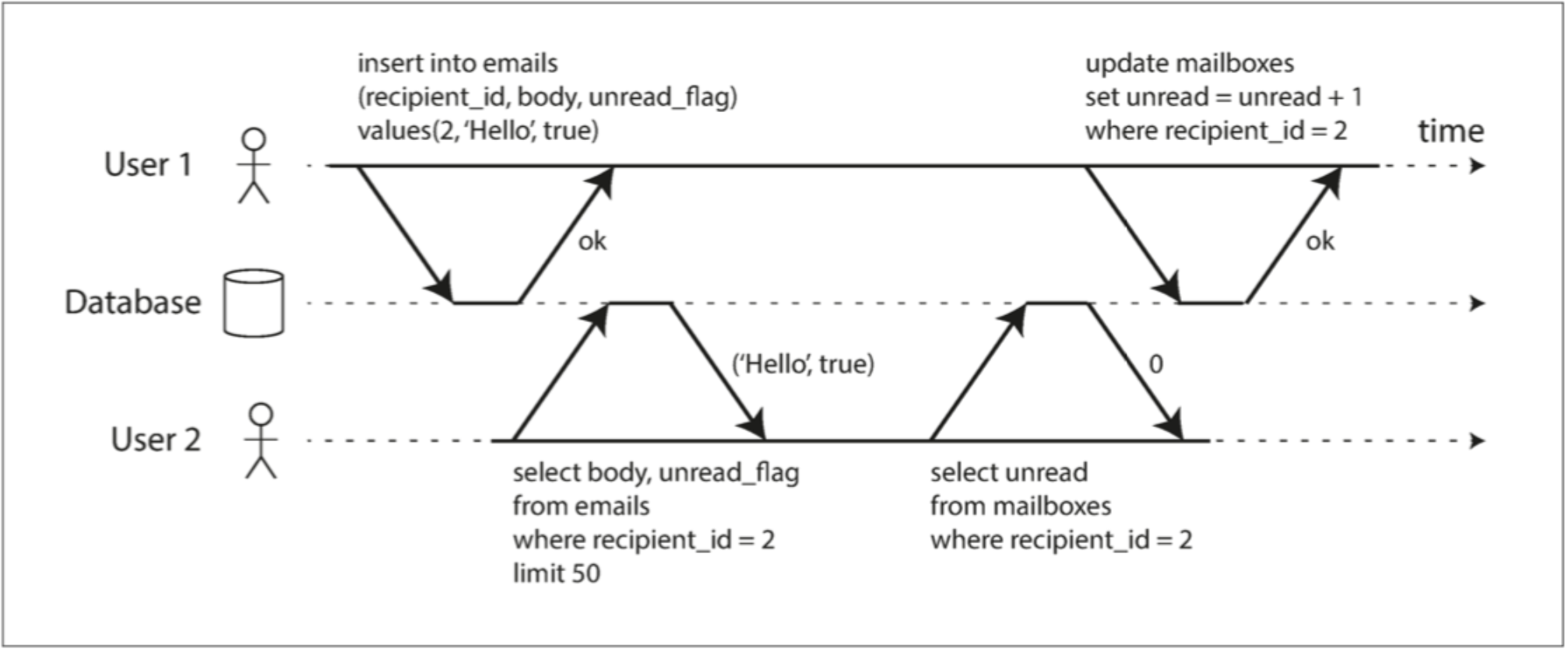 图 1.0 违反隔离性:一个事务读取另一个事务的未提交的写入
图 1.0 违反隔离性:一个事务读取另一个事务的未提交的写入
为什么不能读取一个事务未提交的写入?是因为一个未提交的写入,其后续可能会被终止,终止后该事务的所有写入都会被回滚;若一个事务读取到了另一个事务未提交的变更,而该事务回滚后,程序将得到一个完全不应该存在的值。
Durability(持久性)
事务的持久性是一个承诺,即一旦事务成功提交,即使发生硬件故障或数据库崩溃,写入的数据也不会丢失。
这只是一个美好性承诺,我们小心翼翼地祈祷不会出现如硬盘被偷、文件损坏等故障导致的数据丢失。虽然这有点杞人忧天,不过也说明了并不存在绝对 100% 的保证。
事务的隔离级别
为了简化应用程序在面对并发时的各种问题,大部分关系型数据库都提供了不同的隔离级别。隔离级别并不是一个什么高深的概率,只是数据库系统在简化并发问题时的抽象。不同的隔离级别对应不同的保障,保障系数越高,相应的性能就越低。在选择不同的隔离级别前,我们应该思考该隔离级别提供了什么样的保障?相同的代码在不同的隔离级别下可能会存在什么问题?不同的隔离级别可能会带来什么问题?而不是一味为了应付面试而了解的诸如脏读、幻读、不可重复读、MVCC 等抽象的概念。
Read Committed
正如名字一样,在 Read Committed(读已提交)隔离级别下,一个事务只能读取已提交的数据(对照上面隔离性时的例子)。如下面的例子中,在 User1 未提交前,User2 前两次读取的结果都相同,而当 User1 提交后,User2 就能读取到提交后的数据。
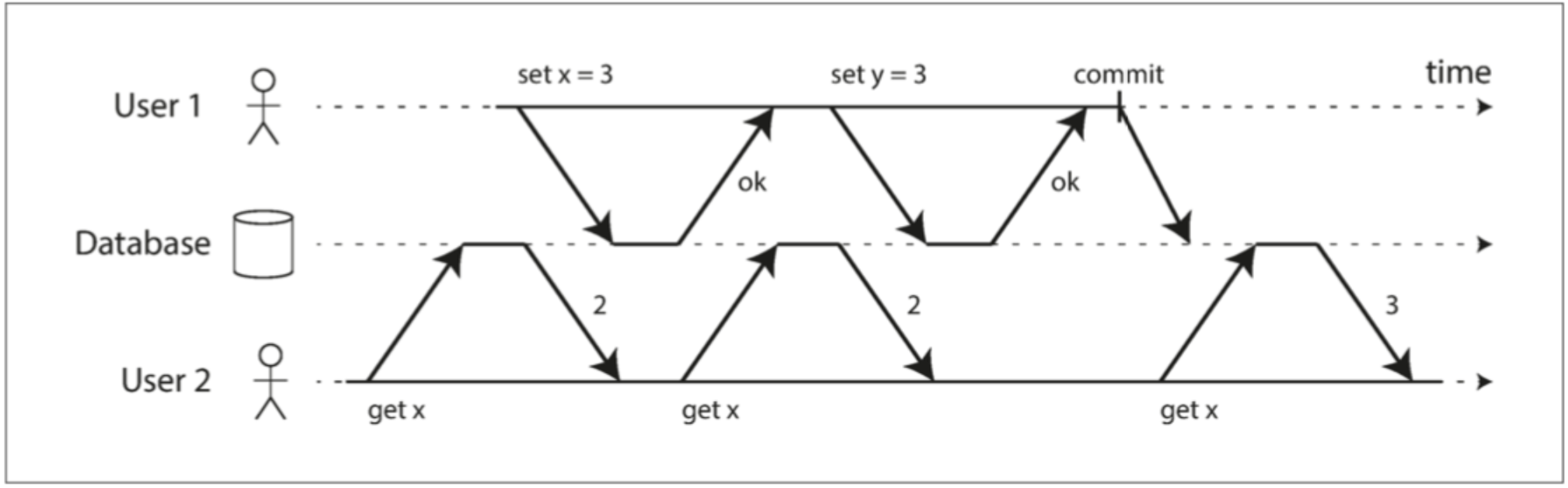 图 2.0 Read Committed User2 在 User1 提交后才能看到新值
图 2.0 Read Committed User2 在 User1 提交后才能看到新值
Read Committed 的实现
Read Committed 是 Oracle 11g、PostgreSQL 的默认隔离级别,通常采用加锁来防止并发写入(写写)。一个事务在尝试更新(写入)对象时,必须先获得该对象的锁,同一时刻只能有一个事务持有该对象的锁,未获得锁的事务需要一直等待,直到持有锁的事务提交或终止。此种方式相当于将两个并发写请求通过加锁的方式串联起来,使得同一时刻最多只允许一个事务进行写入,也就不会存在数据竞争等情况。
几乎所有的数据库系统都允许多个事务并发读取(读读),并发读取数据时并不会对资源加锁,在 Read Committed 和快照隔离级别下,写操作也不会柱塞读操作。
若存在读写并发时(读写),写操作的事务会记录所操作资源的两个版本,一个是原始值,一个是修改后的新值;读事务写事务提交前,都只能读取到原始值,而看不到新值。只有当写事务提交后,读事务才能读取到他提交后的新值。
如图 2.1 所示,写操作把 ID 为 1 的记录从 18 更新到 28,但未提交;其内部可以简单的理解为有一个指向上一个版本的「链接」,通过这个「链接」就能获取上一次已提交的值。读操作在检索到这一对象时(where id = 1),由于最新值 28 是 UnCommitted,将通过「链接」获取上一次已提交的值作为查询的返回值,既返回 18。
 **图 2.1 Read Committed **
**图 2.1 Read Committed **
通过这种方式,Read Committed 就能保障读取到的数据,一定是已经提交了的。
Read Committed 带来的问题
Read Committed 相较于其他隔离级别,不但提供了较好的性能,并且能够满足绝大多数的应用场景,但这并不代表它就是完美的。如下面的例子,在一个事务中,程序筛选满足条件的记录数量,若数量大于 0,再获取相应的数据集合,并返回记录条数和数据集本身。
考虑到当事务执行完第一个查询条件后,另外的事务新增了几条数据并提交,由于在 Read Committed 隔离级别下,事务能读取到另一事物已提交的更新,这将导致后面一次查询出来的数据集条数和第一次查询的 count 不匹配(不可重复读问题)。
start transaction;
count = select count(1) from t where foo = bar
if count > 0 {
return {
count,
datas: select x from t where foo = bar
}
}
commit;
Read Committed 认为这种问题是可以被接受的,也没打算解决这一问题;因为当你重新执行一遍事务,你可能会得到正确的数据。
Snapshot Isolation(快照隔离)
快照隔离(Snapshot Isolation)相比于 Read Committed 提供了更严谨的保障,在 Read Committed 的基础上,还能解决上述的不可重复读现象。这也是 MySQL InnoDB 的默认隔离级别,在 MySQL 中快照隔离被称为可重复读(repeatable read),其名字在不同的数据库系统实现中有不同的叫法,我们只需要知道其具体原理即可。
Snapshot Isolation 的实现
快照隔离在处理多事务并发写入(写写)和多事务并发读取(读读)时,采用与 Read Committed 一样的机制,既允许「读与读」并发而「写与写」互斥。参考 [Read Committed 的实现](Read Committed 的实现)。
在处理多事务并发读写时(读写),不同于 Read Committed,快照隔离通常会保留所操作资源的多个版本,并在每个版本中记录更新数据时的事务 ID(事务 ID 在事务开始时由数据库系统分配,通常是单调递增的)。如图 3.0 所示,记录了 ID 为 1 的数据更新历史,其值先后被更新为 0 -> 6 -> 15 -> 18 -> 28,其事务 ID 依次为 1、3、5、7、9;最后一次更新操作暂未提交。
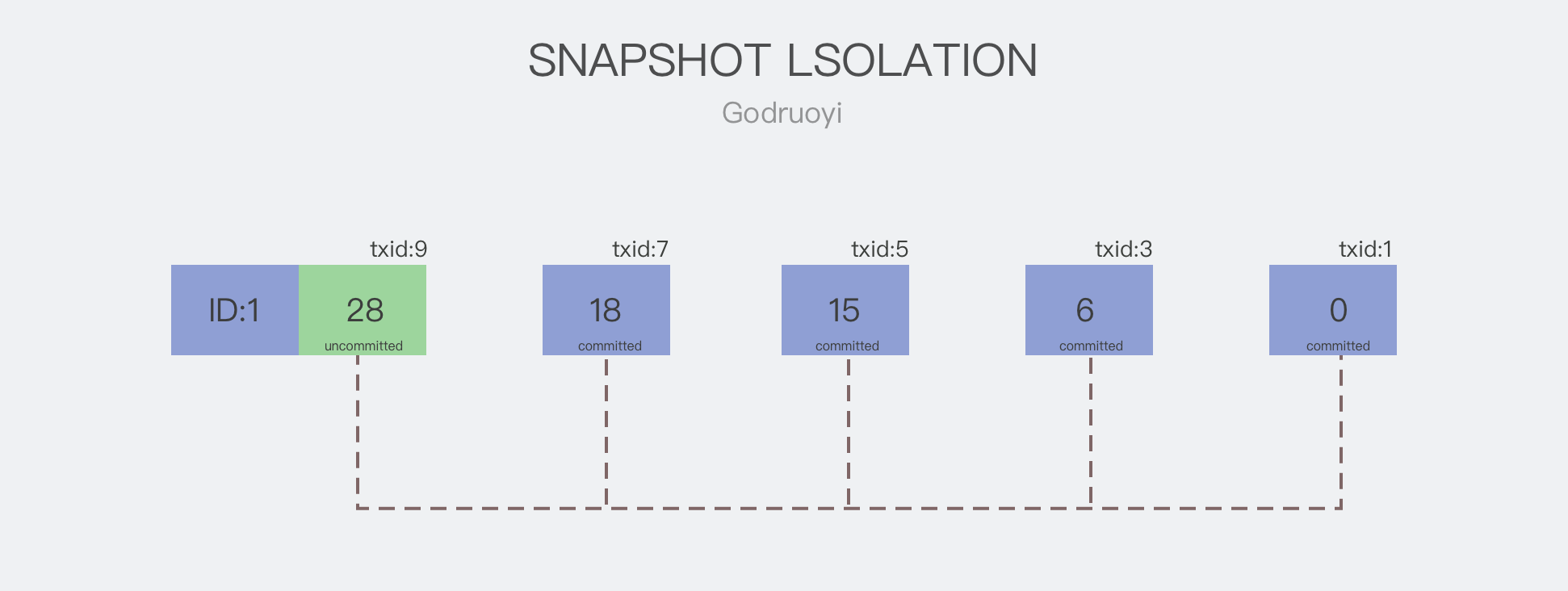 图 3.0 多版本控制
图 3.0 多版本控制
读操作在读取数据时,会过滤事务 ID 大于自身的版本。假设有一个读事务正在读取 ID 为 1 的这条记录,其 txid 为 6,由于程序运行较慢,该记录已经向前提交了两个版本,既上图的 txid 为 7、9 的两次提交;则读操作在查询时,只会获取 txid<=6 并且已提交的版本作为查询的返回值,所以查询将返回 {txid:5, value: 15}。
通过这个机制,事务在整个生命周期内进行的多次查询,都将使用同一个版本的数据,即使查询的对象已经提交了多个版本,查询时都将使用事务开始时的数据。相当于在事务启动的时候就生成了一个一致性快照,但这个快照并不是一个数据备份,其并没有 Copy 数据的开销,而是在运行时通过 txid 动态计算的不同版本。
Snapshot Isolation 带来的问题
快照隔离和 Read Committed 都通过「写与写互斥」来解决多事务并发写入的问题,但在某些场景下这种方式并不能保障数据的正确性,其中最主要的就是丢失更新问题(Lost Update)。
如图 3.1,两个并发请求开始读取到的 counter 都是 42,应用程序将值自增后在更新到数据库,最后保存的结果却为 42,User1 的更新被覆盖了。
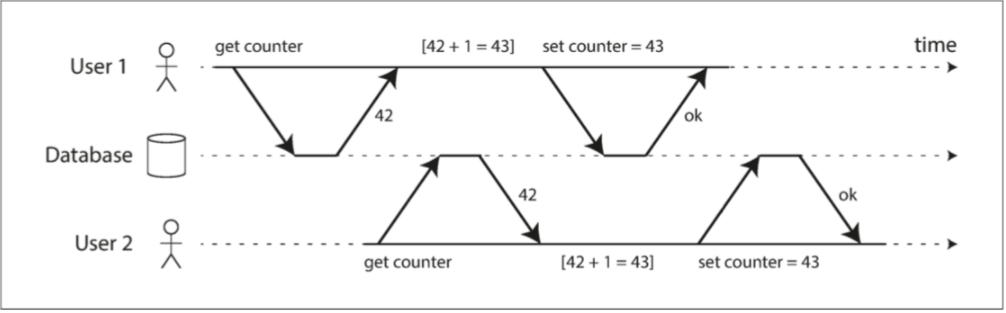 图 3.1 Lost Update
图 3.1 Lost Update
更新丢失准确来说不算是数据库的问题,也不应该要求数据库做出这方面的保障,毕竟数据库在保存数据时,并不知道数据本身的合法性。通常,更新丢失有以下几种解决办法:
- 原子写
update t set count = count + 1 where id = 1
- 排它锁(FOR UPDATE)
通过在 SQL 语句后面指定 FOR UPDATE 来锁定查询条件返回的记录数,在事务未提交期间,其他查询&写入必须等待。
start
select count from t where id = 1 for update
count ++
update t set count = count where id = 1
commmit
Serializable
最后一种隔离级别是可序列化,可序列化隔离通常被认为是最强的隔离级别。他将多个并发执行的事务串行化,一个事务必须等待之前的任务处理完成后才能接着处理。这种隔离级别可以防止所有可能的竞争条件。
- Serializable 的实现
Serializable 通常采用两阶段锁(two-phase locking,2PL)的方式来实现。他允许多事务并发读取,既读与读之间互不干涉。但如果要对某一对象进行写入时,需要等待该对象上的所有读&写事务完成后,才能写入;如果要对写入的对象进行读取时,需要等待写入事务提交或终止后,才能读取。
- Serializable 带来的问题
由于两阶段锁在遇到写操作时,都会对资源进行加锁,并且写操作还会柱塞读操作。所以 Serializable 带来的性能十分低下。并且还可能会发生死锁和写放大等现象,毕竟在生产环境中,当其中一个服务读写变慢时,他就有可能会拖坏整个应用的吞吐率,并逐渐扩大至整个程序不可用。这也是 Serializable 即使提供了更好的隔离级别却很少使用的原因。
总结
数据库事务为我们提供了一个良好的抽象,让开发人员不在担心各种不可靠的环境,不在关心各种模凌两可的状态。有一点需要知道,事务不是天然存在的,我们不要想当然的以为他能够处理好所有的问题,而不考虑他在不同场景下可能带来的影响。
虽然文章标题叫做「为什么我们需要数据库事务」,但其实作者大部分篇幅都在写隔离级别,因为我发现再解释完为什么后,还需要接着解释 Why,那姑且就这样吧。如果你觉得文章对你有帮助,你也可以订阅作者的博客 RSS 或直接访问作者博客 二愣的闲谈杂鱼。